[네이버 클라우드] 멀티클라우드를 여행하는 개발자를 위한 안내서 (1)
클라우드 컴퓨팅은 참 매력적인 기술이다. 발전하는 IT 생태계에서 강력한 인프라를 제공할 수 있는 방법으로 이미 많은 회사들이 클라우드를 도입하고 있다. 물론 온프레미스 환경과 클라우드
kiku99.tistory.com
지난 글에선 NKS에 Cloudforet 서비스를 올리는 단계까지 진행했다. 이번에 할 일은 네이버 클라우드의 리소스를 수집하는 Collector 플러그인을 제작하는 것이다.
Collector 플러그인은 gRPC를 통해 동작하며 spaceone에서 제공하는 명세에 맞게 api를 작성하면 된다. 현재 작성해야 하는 api는 init, verify, collect 라고 볼 수 있다.

그렇다면 데이터는 어떻게 가져오고 처리되는 것인지 간단하게 살펴보자. 큰 흐름은 네이버 클라우드 api를 호출하는 부분은 connector가 담당하고, 수집한 데이터를 처리하는 부분은 manager가 담당한다. 최종적으로 처리한 데이터를 api에게 넘겨주게 된다.
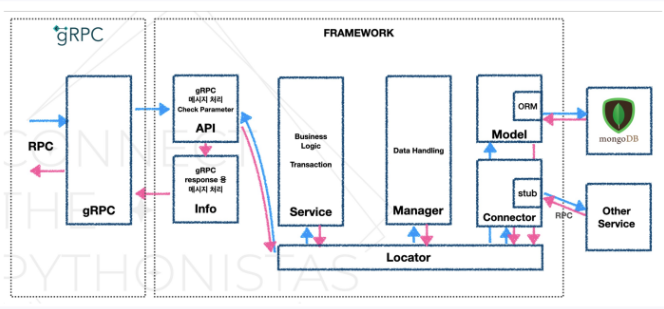
아래 사진은 이전 core framework의 구조인데 현재는 새로운 core framework으로 교체해서 구조가 살짝 다르다. 하지만 전반적인 흐름은 동일하다.
https://github.com/NaverCloudPlatform/ncloud-sdk-python
GitHub - NaverCloudPlatform/ncloud-sdk-python: Naver Cloud Platform Client Library for python
Naver Cloud Platform Client Library for python. Contribute to NaverCloudPlatform/ncloud-sdk-python development by creating an account on GitHub.
github.com
플러그인을 만들기 전에 sdk를 확인해보았다. 현재 네이버 클라우드에서 제공하는 python sdk가 있는데 총 10개의 서비스를 지원한다.

우선 가볍게 server 리소스를 먼저 수집해보자.
데이터를 수집하기 전에 우선 간단한 네이버 클라우드 서버를 하나 띄워야 하는데, 전부터 테스트 용도로 사용하던 서버 인스턴스를 사용하면 될 것 같다. 얘는 서버 타입이 micro라 1년간 무료로 이용할 수 있다.

이제 해당 서버 인스턴스의 리소스를 수집하는 Collector 플러그인을 만들 차례다. 시작해보자!!
1. api 작성하기
gRPC 서버와 통신할 api를 만들어야 한다. 명세에 맞게 init, verify, collect 메서드를 만들어 봅시다.
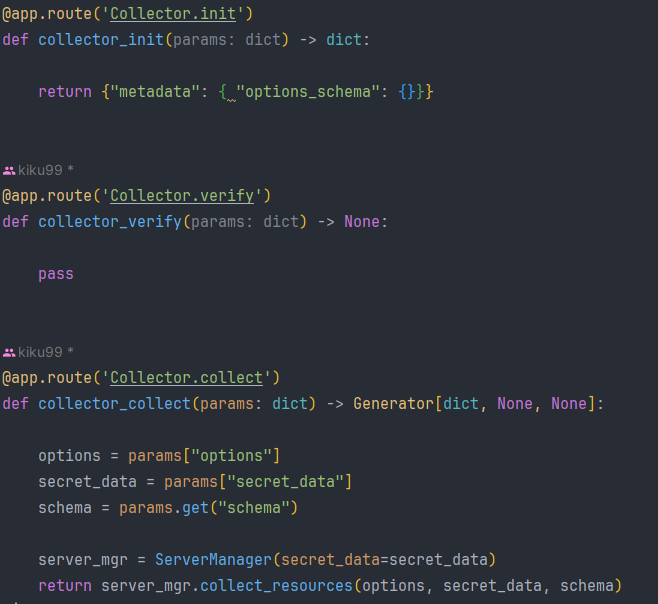
main.py에 위와 같은 코드를 작성했다. 여기서 가장 중요한 메서드는 collector_collect() 메서드다. 실제로 리소스를 수집하는 역할을 맡았기 때문이다. 서버 매니저를 통해서 데이터를 수집하는 로직인데 매니저에 대해선 좀 더 뒤에서 살펴보자. 그리고 collector_verify()는 현재 중요한 메서드가 아니기 때문에 넘겨두었다.
이제 리소스 수집을 도와줄 여러 친구들을 만들어야 하는데 전반적인 패키지 구조는 아래와 같다.
.
├── __init__.py
├── connector
│ ├── __init__.py
│ └── server_connector.py
├── main.py
├── manager
│ ├── __init__.py
│ └── server_manager.py
└── metadata
└── spaceone
├── __init__.py
└── server.yaml
2. Connector 작성하기
Connector는 네이버 클라우드 api를 통해 직접 데이터를 수집하는 역할을 맡고 있다. 코드를 작성해 데이터를 수집해보자.
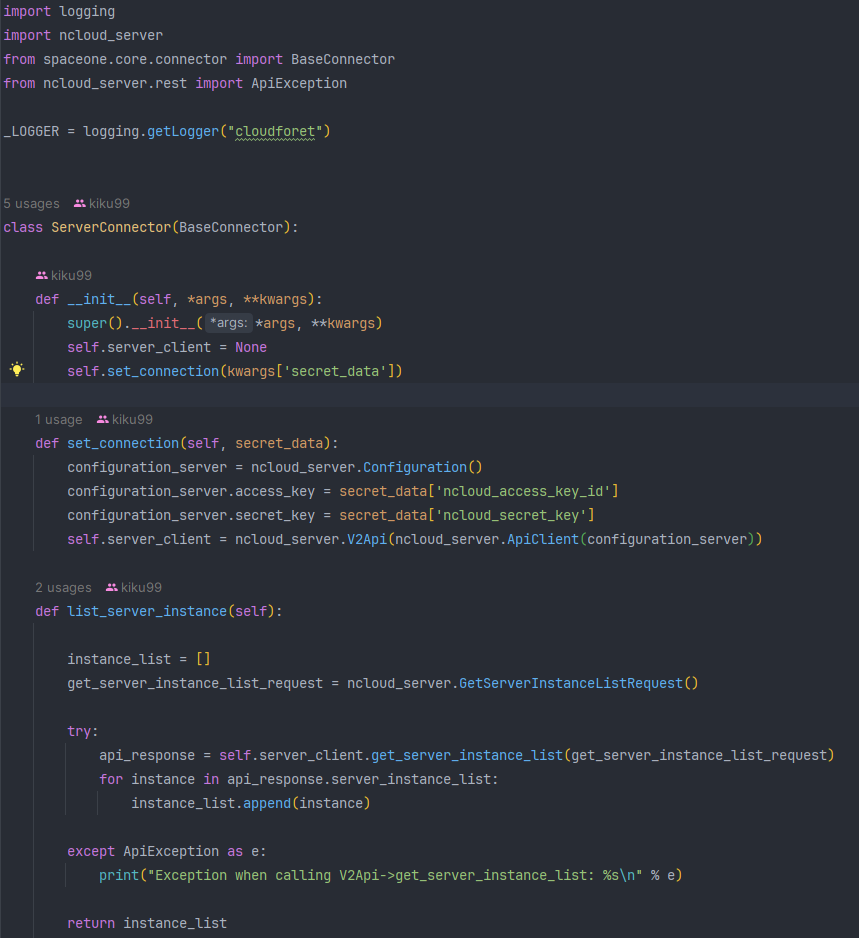
우선 set_connection()을 통해 네이버 클라우드 계정과 연결해준다. 이때 계정의 access key와 secret key가 필요하다. 계정 연결과 동시에 server client도 생성해준다. 이 server client가 직접 데이터를 가져오는 역할을 맡게 된다.
list_server_instance()는 계정의 서버 인스턴스를 수집하는 메서드다. 위에서 만든 server client를 사용해 네이버 클라우드에서 제공하는 api를 통해 데이터를 가져와 각 인스턴스들을 리스트에 담아 리턴하도록 작성했다.(당연히 인스턴스가 여러개일 수 있기 때문)
https://api.ncloud-docs.com/docs/compute-server-getserverinstancelist
getServerInstanceList
api.ncloud-docs.com
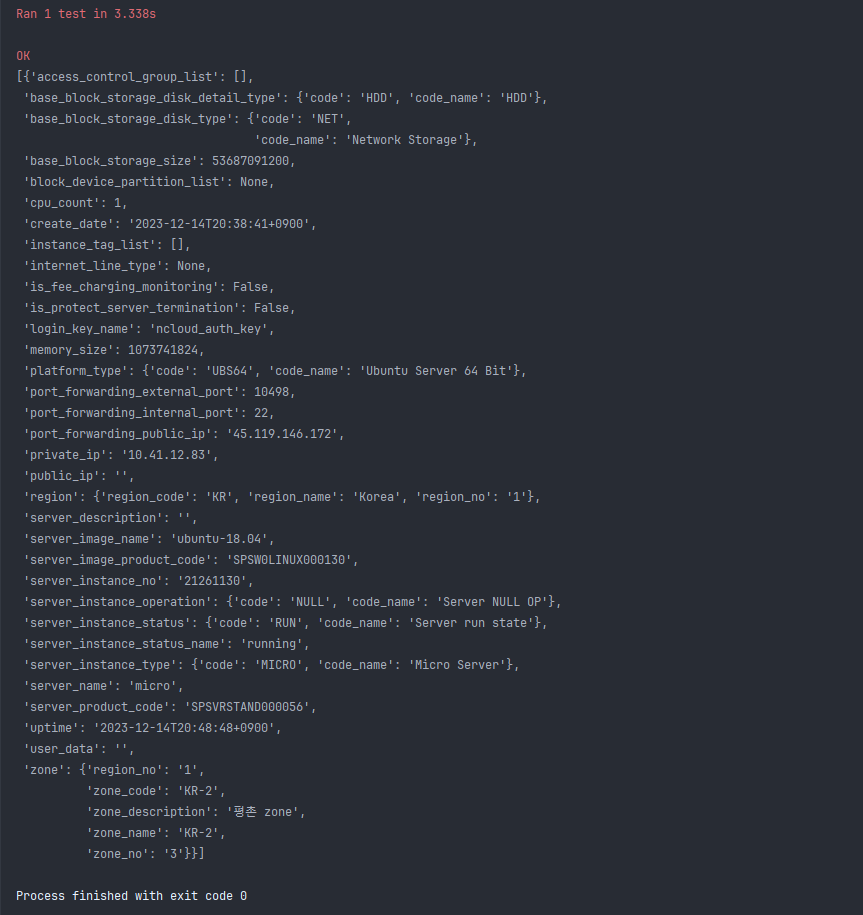
작성한 connector를 테스트하기 위해 테스트 코드를 작성하고 실행해보았다. 결과는 대성공. 만들어둔 서버 인스턴스의 리소스가 잘 수집되는 모습을 볼 수 있다.
3. Manager 작성하기
Manager는 Connector가 수집한 데이터를 가공하는 역할을 맡고 있다. 최종적으로 리턴해줘야 할 데이터는 크게 2가지가 있는데 cloud_service_type과 cloud_service로 구분할 수 있다.
| cloud service type | 클라우드 서비스를 분류하는 타입 ex) 네이버 클라우드 server |
| cloud service | 실제 동작중인 클라우드 서비스 ex) server instance |
여기서 중요한 데이터는 cloud service다. 동작중인 서비스의 자세한 데이터를 담아서 넘겨줘야 하기 때문에 데이터를 어떻게 정의하고 나눌지 잘 생각해야한다.

api 중 collect() 메서드 호출 시 동작하는 collect_resources()는 위와 같다. 설명했던 대로 cloud_service_type과 cloud_service를 담아서 넘기도록 작성했다. collect_cloud_service() 메서드를 살펴보자.

중요한 부분은 server_data를 정의하고 각각 compute, hardware, port_forwarding_rules, ip로 나누었다는 점이다. 이러한 이유는 단순히 data 이름 아래 다 때려박아 버리면 가독성이 너무 떨어지기 때문에 각 속성에 맞게 데이터들을 분류해주었다. 예시로 compute와 hardware 정보를 가져오는 메서드를 확인해보자.
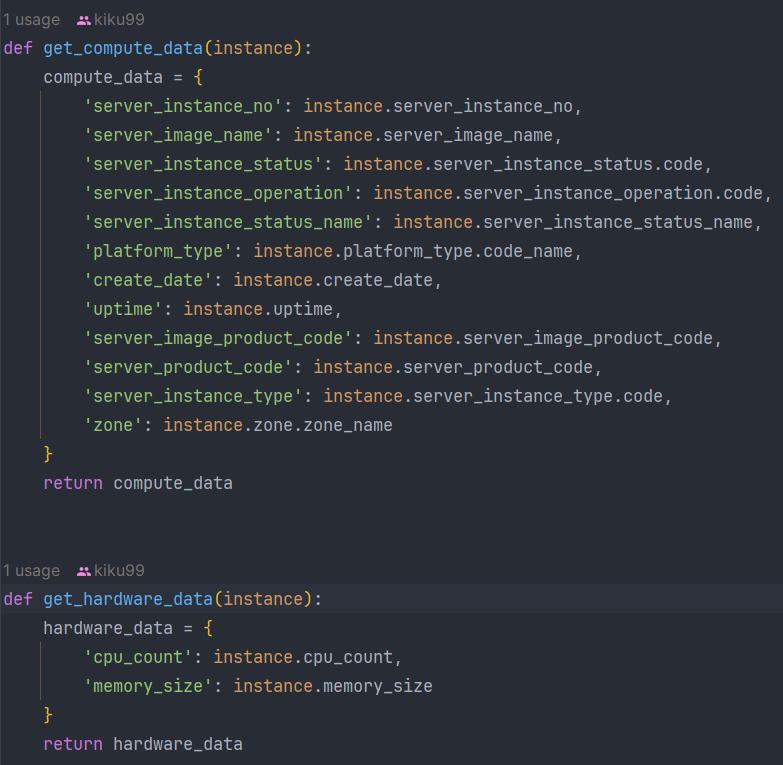
메서드를 보면 각 데이터 속성에 맞게 세부 데이터를 정의하는 모습을 볼 수 있다. 여기서 instance를 참조해 가져오는 데이터는 Connector에서 수집한 리소스들과 정확히 매핑된다. 이런식으로 가공해서 최종적으로 cloud service data를 만들게 되는 것이다.
이제 테스트 코드를 작성해 server manager를 테스트 해보았다.

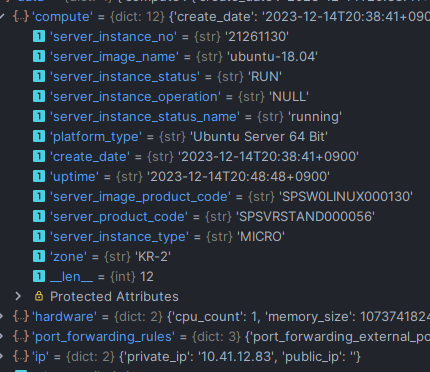
manager에서 정의한 data 구조대로 잘 만들어지는 모습을 볼 수 있다. 정리하자면 아까 Connector를 통해 수집된 리소스들에서 상대적으로 중요한 데이터를 뽑아, 속성대로 구조화했다는 점.
4. metadata 작성하기
metadata는 front-end 쪽에서 사용하기 위한 데이터로 현재는 테스트하기가 어렵다. 왜냐하면 플러그인을 쿠버네티스에 올려야 하는데 아직 도커파일도 만들어지지 않았기 때문. 그래서 그냥 대충 구조만 만들었다.
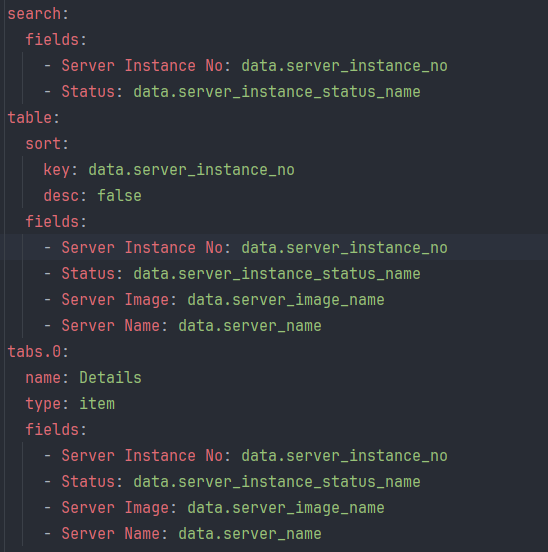
이제 api를 호출하기 위한 친구들을 다 만들었다! 남은건 테스트 뿐.. 가보자고
먼저 api를 테스트하기 위한 gRPC 서버를 켜야한다.

서버가 정상적으로 켜졌으니 api 테스트 코드를 작성해 테스트해보자.
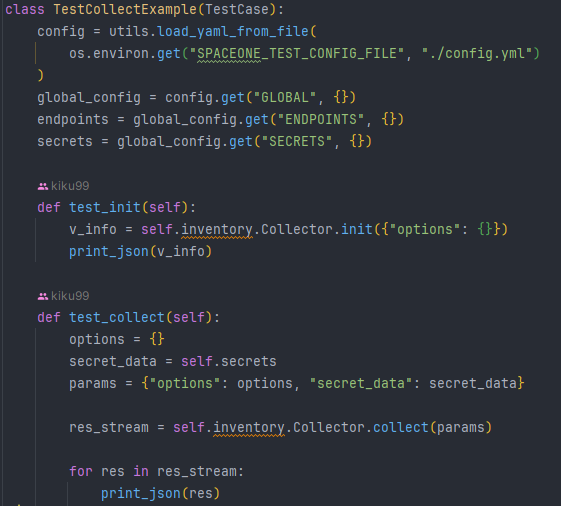

init(), collect() 메서드를 테스트 한 결과 잘 작동했다.
네이버 클라우드 서버 인스턴스의 리소스를 수집하는 플러그인이 어느정도 완성됐다. 물론 metadata나 세부적인 데이터 정리를 해야 하지만 큰 틀은 만들어진 셈. 이제 나머지 서비스들을 추가해서 플러그인을 완성해보자!
3부에서 계속-
'개발 > Cloud' 카테고리의 다른 글
| [네이버 클라우드] 멀티클라우드를 여행하는 개발자를 위한 안내서 (3) (0) | 2024.05.31 |
|---|---|
| [네이버 클라우드] 클로바노트를 만나고 나의 커피인생 달라졌다(feat.CLOVA Speech) (0) | 2024.01.29 |
| [네이버 클라우드] Load Balancer 살펴보기 (0) | 2024.01.14 |
| [네이버 클라우드] Auto Scaling 살펴보기 (1) | 2024.01.09 |
| [네이버 클라우드] VPC 살펴보기 (0) | 2023.12.31 |