요새 내가 사용하는 브루잉 레시피가 다양해지면서 노트에 정리할 필요가 생겼다. 원래 노션에 정리하다가 이번에 애플 노트에 다시 작성했다.
한 레시피만 쓰지 않고 매번 바꿔가면서 사용하기 때문에 레시피를 외우기가 쉽지 않더라. 그래서 항상 메모장을 보면서 커피를 내리는 편이다.


보통 핸드드립 레시피는 국내 바리스타의 레시피를 사용하기도 하지만 해외에도 굉장히 뛰어난 레시피들이 많다. 예를 들면 내가 애용하는 테츠 카스야 바리스타의 4:6 같은 레시피들이 있다.
이런 유명 바리스타들은 유튜브를 통해 레시피를 직접 소개하는 경우도 있어서 세계 챔피언의 레시피를 내가 직접 사용할 수 있기도 하다.
https://youtu.be/lJNPp-onikk?si=RxCIF0K7iCKD-Yyv
다만 문제가 있는데 내가 일본어를 아예 못한다는 점이다. 위 영상은 영어 자막이라도 있지만 보통은 없는 편이다. 20분이 넘는 영상들을 자막 없이 보기엔 일알못인 나에게 굉장히 어려운 일이었다.ㅠㅠ

그러다가 최근에 네이버에서 출시한 음성 기록 관리 서비스인 클로바노트를 알게 되었는데, 요게 일본어도 되고 AI를 통해 요약까지 해준다는걸 확인했다. 과연 일본어로 된 레시피 영상을 분석하고 요약하는데도 쓸 수 있을지 확인을 해보기로 했다.
그전에 네이버에서 제공하는 음성 인식 서비스인 CLOVA Speech에 대해 살펴보고 가자.
Naver Cloud CLOVA Speech

CLOVA Speech는 음성을 텍스트로 변환하는 서비스로 음성 메모, 영상 자막 생성, 통화 녹취록 등 긴 음성, 비서 애플리케이션, 챗봇 등 짧은 음성에 따른 최적 음성 인식 엔진을 제공한다.
CLOVA Speech는 NEST (Neural End-to-end Speech Transcriber)라는 음성인식 엔진을 사용하는데 음향 정보와 언어 정보를 별도로 학습하는 기존의 모델링 방식을, 통합 모델링 방식으로 개선했다고 한다. 따라서 대량의 정제된 데이터를 학습하지 않고도 정형화되지 않은 길고 복잡한 문장에 대해 정확한 음성 인식을 제공한다.
좀 더 자세히 알아보기 위해 ASR 기술에 대해 이야기해보자.
ASR이란?
ASR(Automatic Speech Recognition) 이란 사람이 말하는 음성 파형을 컴퓨터가 자동으로 문자 데이터로 변환하는 기술이다. 흔히 Speech-To-Text, STT 라고도 불리기도 한다.
예전에는 모델을 음향(Acoustic), Lexicon, 언어(Language) 3가지 부분으로 나누고, 각 부분들을 서로 독립적으로 모델링하는 HMM-GMM 방식을 사용했다.

하지만 HMM 기반의 방법은 음성 인식 Task를 3가지로 나누었기 때문에 나타나는 단점들이 몇가지 있었다.
각각의 모델들에서 최적의 성능을 만들었다 하더라도 이것이 ASR 모델 전체에서 최적의 성능을 내지 못하거나, HMM 계산의 간결성을 위해 조건부 독립을 가정했는데 이로 인해 실제 계산과의 차이가 생기는 경우도 있었다.
여기서 CLOVA Speech가 사용하는 E2E(End-To-End) 모델이 등장한다. 딥러닝이 발달하면서 딥러닝 기반의 E2E 모델을 사용하기 시작했고, 실제로 성능 향상을 이루었다고 한다. 그렇다면 E2E 모델은 무엇일까?
E2E(End-To-End) ASR
E2E ASR 모델은 음향 입력에서 특징(feature)을 추출하는 특징 추출기(feature extrator)과 feature와 레이블 출력 사이의 정렬을 맞추는 부분, 최종 결과를 디코딩하는 디코더로 구성되어있다.
HMM과는 달리 모든 부분들이 별도의 훈련 과정 없이 한번에 함께 훈련된다는 특징이 있다. 그렇기 때문에 별도의 모델링이 필요하지 않고 목적 함수에 맞는 최적 값을 얻을 수 있다.

쉽게 얘기하면 입력되는 음성의 특징을 추출하고, Acoustic Model을 통과하고, decoder에서 후처리를 진행하는 파이프라인 방식이라고 이해할 수 있다. 이런 E2E ASR을 서비스하기 위해 여러가지 방법이 제시되었는데 가장 최초에 등장한 모델은 CTC(Connectionist Temporal Classification) 방식이다.

CTC 모델의 컨셉은 directional RNN(혹은 LSTM)을 여러층 쌓고 인코더로 들어오는 입력 데이터는 최종적으로 Softmax를 통과해서 결과를 출력하는 방식인데, 전체 sentece를 입력으로 넣고 처리하다보니 Streaming에는 적합하지 않은 여러가지 문제가 발생했다. 따라서 이를 보완하기 위해 Online Model이 등장했다.
Online Model은 음성을 처리할 수 있도록 구조적으로 설계된 모델인데, 대표적으로 RNN-Transducer, NT, MoChA 등이 있다. 여기서 RNN-T를 살펴보면 Encoder에 Prediction Network를 연결해서 후처리 언어모델의 효과를 얻을 수 있도록 한 점이 기존 CTC 모델과의 차이점이다.

참고) 구글의 RNN-Transducer인 STREAMING END-TO-END SPEECH RECOGNITION FOR MOBILE DEVICES
여기서 CLOVA Speech의 NEST가 정확히 어떤 구조의 모델인지는 잘 모르겠다. Naver DEVIEW 2023 발표자료를 보니까 CTC, AED, RNN-T 모델을 같이 비교한것으로 보아 RNN-T 기반의 모델일지도..?


말이 좀 길어졌는데, 정리하면 네이버가 제공하는 ASR 서비스인 CLOVA Speech는 성능 좋은 E2E 모델을 사용했다는 점. 이제 CLOVA Speech가 제공하는 기능들을 살펴보자.
- 문장 자동 분리 및 타임스탬프 지원: 적절한 길이로 문장을 자동 분리하고 시간을 표시하여 자막 생성 등 다양한 방식으로 활용 가능
- 타임라인 뒤로 밀기 기능: 인식된 텍스트의 타임라인 전체를 뒤로 미는 기능으로, 길이가 긴 영상을 분할하여 자막을 생성할 때 유용
- 배치 기능을 통한 대량 처리: 배치를 생성하여 다수의 미디어 파일에 대한 인식 작업을 일괄 처리
- 웹 빌더 및 인식 결과 수정 에디터 제공: 인식 작업을 손쉽게 관리할 수 있는 빌더 및 인식 결과를 편집하고 내보낼 수 있는 에디터 제공
- 키워드 부스팅: 인식 확률을 높이고 싶은 단어 설정
- API 기반 인식 제공: CLOVA Speech API를 이용한 인식 대상 파일 전송 및 인식 결과 받기 가능
내가 기대되는 기능은 문장 타임스탬프 기능과 키워드 부스팅 기능이다. 요 기능들을 통해 브루잉 레시피를 작성할 때 도움이 많이 되지 않을까 하는 생각이 든다.
CLOVA Speech는 도메인을 생성하여 도메인별로 인식 작업을 관리할 수 있다. 따라서 콘솔에서 도메인을 생성해야 한다.

생성된 도메인을 통해 인식 대상 파일 및 결과 파일의 저장 경로를 설정할 수 있으며, 도메인별로 제공되는 빌더를 통해 인식 작업을 요청할 수도 있다. 예시로 단문 인식 빌더를 실행하는 화면을 보자.
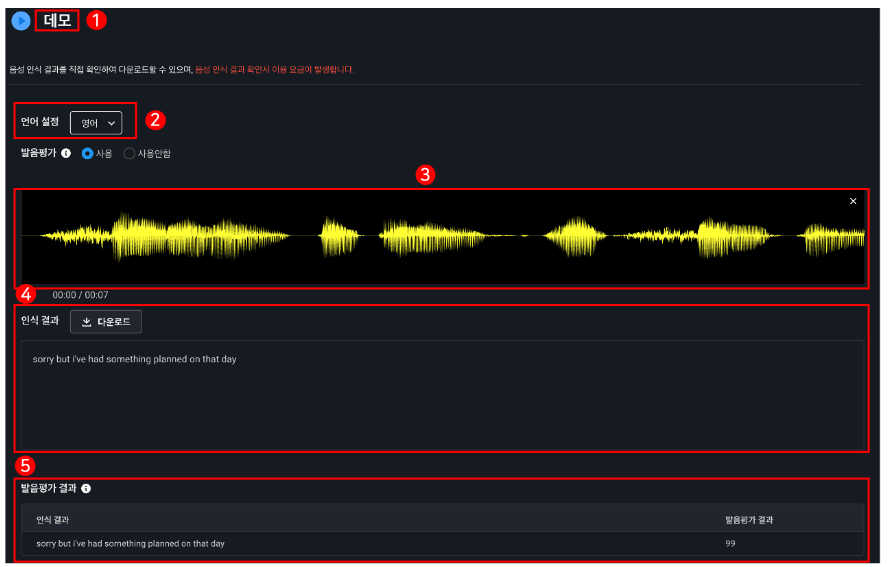
이런 식으로 콘솔에 음원을 업로드하여 단문 인식 데모 기능을 사용할 수도 있다. 인식 결과는 화면으로 확인이 가능하다.
정리하자면 우리는 API나 네이버 클라우드 콘솔을 통해 ASR 서비스인 CLOVA Speech를 이용할 수 있다. 하지만 아무래도 일반인이 사용하기에는 어려운 점이 있다. 여기서 클로바노트를 사용한다면 좀 더 편리하게 사용할 수 있다!
https://blog.naver.com/clova_ai/223184896850
[클로바노트] 정식 버전 출시 안내 - 더욱 새로워진 클로바노트를 만나보세요!
안녕하세요, 네이버 클로바노트 팀입니다. 클로바노트 정식 버전에서는 모바일 앱과 PC 어디서든 녹음이 ...
blog.naver.com
드디어 브루잉 레시피를 클로바노트를 통해 작성할 차례다. 두근두근
우선 녹음을 하기 전에 인식 언어를 설정해줘야 한다. 일본어 영상이기 때문에 일본어로 설정해주었다.

언어를 설정한 후 바로 녹음을 시작했다. 결과가 몹시 궁금한 상황..

대략 26분간의 녹음을 마치고 결과를 보니 뭔가 멋지게 나왔다. 참석자 별로 나누어 대화형으로 텍스트가 뽑혔는데 신기했다. 저 영상도 인터뷰어와 바리스타 서로 대화를 하면서 레시피를 설명하는 영상이기 때문. 물론 바리스타가 말하는 비중이 매우 높긴 하다.

다만 아쉬운 점은 번역 기능이 없다는 점이다. 그래서 외부 번역기를 통해 한국어로 번역을 해줘야하는 번거로움이 있다. 정식 출시한지 얼마 안된 서비스니까 그럴 수 있어~ 나중에 번역 기능도 꼭 넣어줬으면 좋겠다. 네이버 파파고도 있으니 어려운 일은 아닐듯.

그리고 또 아쉬운 점은 한국어를 제외한 다른 언어는 요약 기능이 지원을 안한다는 점. 이건 확실히 아쉬운 부분이긴 했다. 요약된 내용이 궁금했지만 어쩔 수 없지.
그래도 테츠 카스야가 무슨 말을 하는지 알아들을 수 있어서 너무 좋았다. 솔직히 정량적인 레시피를 찾으려면 찾을 순 있지만 영상에서 주저리 주저리 말하는 내용들이 그동안 너무 궁금했다.
보통 브루잉 레시피는 바리스타의 철학이 녹아있기 마련이다. 가령 어떤 바리스타는 원두의 특징을 최대한 살리려고 한다거나, 밸런스를 중요시 하는 바리스타, 클린컵을 극도로 추구하는 바리스타도 있다. 확실히 레시피만 보는것 보단 전체 영상을 쭉 보는게 레시피를 더 와닿게 느낄 수 있다고 생각한다.
아무튼 클로바노트를 통해 좋은 레시피들을 쉽게 접할 수 있게 되었다. 번역 기능과 요약 기능만 추가 되면 큰 도움이 될 것 같다. 특히 번역기능이 빨리 업데이트가 되면 좋겠다!
참고자료
1. End-to-End Automatic Speech Recognition 개요
이 카테고리는 종단간 자동 음성 인식(End-to-End Automatic Speech Recognition, 이하 E2E ASR)에 대해 작성하는 연작 포스팅입니다. 주요 표기법(Notation)과 내용(Content)은 Speech and Language Processing 2nd Edition(Daniel
ai4nlp.tistory.com
https://jybaek.tistory.com/793
Towards end-to-end speech recognition
본 게시물에서 사용된 대부분의 이미지는 아래 링크로부터 첨부되었으며 해당 자료를 통해 많은 영감을 얻었습니다. http://iscslp2018.org/images/T4_Towards%20end-to-end%20speech%20recognition.pdf 하루가 멀다하
jybaek.tistory.com
https://blog.naver.com/clova_ai/221952107312
[Speech] 길고 복잡한 말도 정확히 인식하는 기술 NEST
AI Product CLOVA Speech - 클로바 스피치 NEST 엔진 - CLOVA AI Product 란 클로바...
blog.naver.com
'개발 > Cloud' 카테고리의 다른 글
| [네이버 클라우드] 멀티클라우드를 여행하는 개발자를 위한 안내서 (3) (0) | 2024.05.31 |
|---|---|
| [네이버 클라우드] 멀티클라우드를 여행하는 개발자를 위한 안내서 (2) (2) | 2024.01.17 |
| [네이버 클라우드] Load Balancer 살펴보기 (0) | 2024.01.14 |
| [네이버 클라우드] Auto Scaling 살펴보기 (1) | 2024.01.09 |
| [네이버 클라우드] VPC 살펴보기 (0) | 2023.12.31 |